
The Molecular Blueprints for Life
Depending on how long you've been following me for, you would know that I've already covered the basics of what DNA and RNA is, and how it works. In this series, we'll explore the what makes nucleic acids so special. For one, they are the only biological substance capable of self-replication thus enabling it to pass on information from one generation to the next. Inside this molecular code is information for everything that makes you, you - from the proteins that make your muscles, to the enzymes that allow you metabolise stuff. Mapped out and programmed, much of your development from child to adult, is coded within your very DNA.
A Brief History of DNA
- During the Franco-Prussian war in 1989, the military scientist Friedric Miescher 'discovered' DNA when he was analyzing discarded surgical dressings, to which he found very small quantities of some sort of acid. In this analysis, this acid was found predominantly in the nuclei of white blood cells. Aptly, he named this substance "nuclein".
- In the years 1884 to 1885, the scientists Oscar Hertwig, Albrecht von Kölliker, Eduard Strasburger, and August Weismann all provide evidence (independently) that the nucleus of a cell contain the information for inheritance.
- Four years later, in 1889, Richard Altmann renames Miescher's discovery as "nucleic acids" instead of nuclein.
- By 1910, Thomas Hunt Morgan uses the Drosophila fruit fly to study inheritance, and discovers the white-eyed mutant. Three years later, with his colleague Alfred Sturtevant, they create the first genetic map for a chromosome in the Drosophila fruit fly.
- Frederick Griffith, in 1928, discovered that when a non-virulent strain of bacterium (Streptococcus pneumoniae) are able to become virulent when mixed with heat-disabled virulent strains. He called this the "transforming principle."
- In 1929, Phoebus Levene discovers the building blocks of DNA.
- In 1942, George Beadle and Edward Tatum make the discovery that genes are responsible for the production of proteins.
- In 1944, Oswald T. Avery, Colin MacLeod, and Maclyn McCarty demonstrate that a discovery made in 1928 by Frederick Griffith is not the result of proteins being transferred between bacteria. Highly suggesting that nucleic acids are the genetic material.
- From 1949 to 1950, Erwin Chargaff discovers that the base composition discovered by Phoebus Levene varies between species in different quantities.
- Using the T2 bacteriophage, in 1952, Alfred Hershey and Martha Chase discover that it is the genetic material of virus, not the proteins that infect the bacterium.
- By 1953, Rosalind Franklin used x-ray diffraction to produce high-resolution images of the DNA structure, suggesting that it has a double-helix shape. Later that year, Francis Crick and James Watson produce the first model of DNA - a double helix in which the bases A always pairs with T, and C with G. Their discovery was published in April 25 1953 in the magazine Nature.
- Matthew Meselson and Franklin Stahl discover how DNA replicates in 1958.
- From 1961 to 1966, Robert W. Holley, Har Gobind Khorana, Heinrich Matthaei, Marshall W. Nirenberg and their colleagues manage to figure out what some genes code for what amino acids. "Cracking" the genetic code.
- Paul Berg, in 1972 manages to create the first bit of recombinant DNA. By 1977, Frederick Sanger, Allan Maxam, and Walter Gilbert create the first method of sequencing DNA.
- In 1982, the first commercial application of DNA technology using recombinant DNA is produced - human insulin becomes widely available and much easier to produce. A year later, Kary Mullis discovers the polymerase chain reaction (PCR) as a way to produce many copies of DNA in vitro.
- After eight years, the sequencing of the human genome begins in 1990, which is only completed and then published 11 years later in 2001. The next year, the first genome of the model mammalian organism, the mouse, is completed.
The DNA molecule is recognised by everyone - the hallmark double helix structure is the go-to image for biosciences. With it, it has changed the way we think about the living world - it is the result of more than 100 years of hard work and dedication. Understanding DNA has lead us to develop new technologies to treat illnesses and hereditary diseases, and as demonstrated in 1982. The nature of how genes are passed on has been fundamental to modern agriculture and is responsible for the Green Revolution in the '30s to '60s and to now, where we are able to create hardier and more resilient crops than ever. You can check out my other blog series about Gene Editing here.
Two Types of Nucleic Acids
It is recognised that there are two types of nucleic acid: Miescher has discovered deoxyribonucleic acid (DNA), later it was discovered there was another type of nucleic acid, called ribonucleic acid (RNA). In each case, they are polymers - made of smaller molecules called monomers linked in a large chain. Their differences can be summarised below:
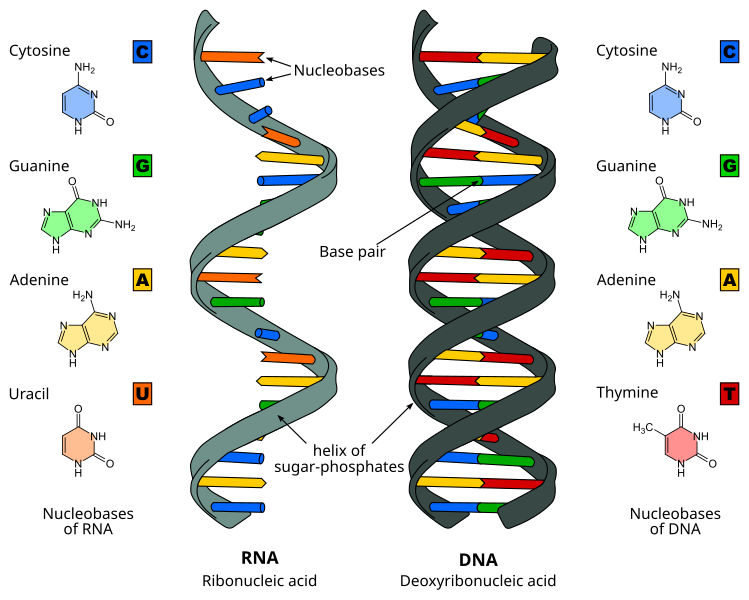
Both RNA and DNA contain three main constituents which make up the nucleotides:
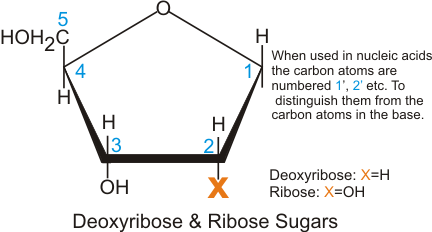
- A five carbon sugar, called ribose in RNA, and 2-deoxyribose in DNA. Their structure differs as below:
- A phosphate group, which forms a phosphodiester link between two sugar residues, forming the back bone of the nucleic acid. You can see how they look below:

- And finally, the nucleobases, which can be seen above and are bonded to the 1' carbon of the sugar. These bases form hydrogen bonds with the adjacent strand, and in the case of mRNA, pair with tRNA to enable protein production. They can be separated into two types: the purines (Adenine and Guanine) and the pyrimidines (Cytosine (and 5-methylcytosine) ,Thymine, and Uracil which is found RNA only). The chemical bond between the carbon 1' of the sugar and the nucleobase is termed as a glycosidic bond.

Nucleotides and their derivatives
As noted above, nucleotides are the monomers that make up the DNA strand and are connected via phosphodiester linkages. Nucleotides are considered to be the phosphorylated derivative of a nucleoside, which lack the phosphate group on the 5' carbon of the sugar group. Large stretches of nucleotides are often called polynucleotides while those with a few are termed oligonucleotides (dinucleotides, trinucleotides, tetranucleotides etc.).
Noted before as well, RNA contains the ribose sugar, in which the 2' OH group is still present, giving it a different function than with the DNA deoxyribose form. This is because the 2' OH group is found in RNA enzymes called ribozymes, which were discovered by Thomas Cech and Sidney Altmann independently. Because of this, many biochemists think that it is possible that RNA came into existence earlier than DNA. DNA is much more stable than RNA, which allows it to be much larger than its ribose counterpart.
Nucleotides are strong acids where the ionization of the phosphate group and the deprotonation/protonation of the bases at pH values around 7. The nucleobases are also capable of converting into different tautomeric forms because of the several double bonds present in the ring structure (a form of conjugation). For example, uracil can convert between the keto and enol forms:
 A consequence of highly conjugated chemical structures is how much the molecules absorb light. Purines, pyrimidines and their derivatives (nucleic acids, nucleotides and nucleosides) all absorb light in the ultraviolet region. You can scroll down on the papers here, and here to see these spectra. Normally we use these spectra to make quantitative measurements at the 260 nm setting on a spectrophotometer.
A consequence of highly conjugated chemical structures is how much the molecules absorb light. Purines, pyrimidines and their derivatives (nucleic acids, nucleotides and nucleosides) all absorb light in the ultraviolet region. You can scroll down on the papers here, and here to see these spectra. Normally we use these spectra to make quantitative measurements at the 260 nm setting on a spectrophotometer.
Another important part of nucleotides are the phosphodiester bonds present in the DNA molecule. These bonds are formed by "adding" a water to the monomers. The opposite is true, hydrolysis removes a water molecule from this bond, releasing a ∆Gº' = +25 kJ/mol, as a result, this is a thermodynamically favoured reaction. See below to see how this looks like:

In the cell, both RNA and DNA are broken down by nucleases, catalysing reaction (2) above, generally this reaction is utilised in metabolic pathways as a way to create glucose, or ketone bodies to produce energy, excess nitrogen is converted into urea and then excreted (more on this in my Metabolism and the Energy of Life series). As discussed in that series, ATP is often used by the body to drive forward reactions that would otherwise be impossible in vivo. The polymerization of nucleotides is such a reaction, leading to the phosphodiester bond's stability.
In fact, DNA is so stable, it has been found in bones recovered to be as old as 80,000 years old. This assisted us in sequencing the complete genome of an extinct human species, the Neanderthal in 2010. The resilience of DNA has also helped us map the genetic distribution of our own species, from Africa to beyond. A truly wonderful molecule!
Now that you've been acquainted with nucleic acids. the next section will go over its primary structure.
As always, thanks for reading!
Links provided bring you to some of the info I used, the first year university textbook, "Biochemistry: Concepts and Connections," 1ED, by D.R. Appling, Pearson Ed. LTD, was used as a guide to write this post. You can buy it here.
No comments:
Post a Comment