
The Function of Nucleic Acids
So far, I've only discussed the main structures of nucleic acids - the primary, secondary and tertiary structures. This section will focus on the function nucleic acids in cells and the denaturation of nucleic acids.
Genetic Biochemistry - from genes to proteins
In my blogs I haven't quit covered the biochemistry of genetics in detail, so think of this part as a (very) brief overview of molecular genetics. It's important to remember that the main function of nucleic acids is to store genetic information and that they are the key to biochemical processes, namely, protein synthesis.
What's in a genome?
All living things carry genes - sections of DNA which, when 'read' by your molecular machinery, result in the expression of a particular gene. Expression leads to the synthesis of a chemical, usually a protein of some description, such as an enzyme. Depending on the organism, their genetic information can be stored as double-stranded DNA or RNA molecules which can vary in length. Genomes are also present in viruses (which aren't considered 'alive'), which generally contain a few thousand bases (b) that code for the proteins that make up the viral structure.
The E. coli bacteria had its circular genome sequenced in 1997, which contains about 4.64 million base pairs (1.6 mm in theoretical length), all of code for about 4000 genes, 50 of which are considered 'non-essential'. Another bacteria, the pathogenic Clostridium difficile has about 4.4 million base pairs. An interesting thing to not about these bacteria is that, even though they contain less genetic material than us, they have a higher gene density than us.
Comparatively, the human genome was sequenced in 2001, we found out that it contains about 3.0 ×109 base pairs (3,200 Mb, megabase pairs). The full sequencing and analysis of our genome revealed that:
There appear to be about 30,000–40,000 protein-coding genes in the human genome—only about twice as many as in worm or fly.
This came as a surprise to many who had thought that we were more complex than other organisms, and the fact that only 1.33x10-5 % of our genome codes for essential proteins. Much of our genome has been termed as 'junk DNA.' It is possible that this junk, referred to as non-coding DNA (ncDNA), is essential for regulation at the genetic level. I'll leave some links at the bottom of this post if you want to read more about this section of our DNA.
Gene Expression: An overview

In most organisms it is those genes that are 'read,' synthesising RNA for use by ribosomes, and thus directing the synthesis of proteins. This process of gene to protein is called gene expression.
Transcription: the first step of gene expression
The first step involves the DNA strand being unwound, by a leading enzyme. Behind it is RNA polymerase, along with other enzymes, which begins to 'read' the DNA strand, which becomes the template for the RNA being produced. It works in a similar fashion to DNA replication, but instead produces a single-stranded RNA molecule, called mRNA. This process is powered by ribonucleoside triphosphates, such as: ATP, GTP, CTP, and UTP, which are all needed to make RNA. Again, similar to to DNA replication, this process requires the use of a class of enzyme called polymerases. Specifically, the RNA polymerases. This process can be summarised below:
1) RNA polymerase bind to the promoter, which begins transcription

2) RNA polymerase goes along the DNA strand, opening up the strand "downstream," while the strand closes "upstream." A strand of RNA is produced which is complementary to the bases present on the template strand:
3) Once RNA polymerase reaches the termination "STOP" codon, it detaches from the DNA strand and a pre-mRNA strand is produced. This is then 'edited' by enzymes, removing non-essential regions called introns (I'm not going to cover this process here).
Translation: proteins from mRNA
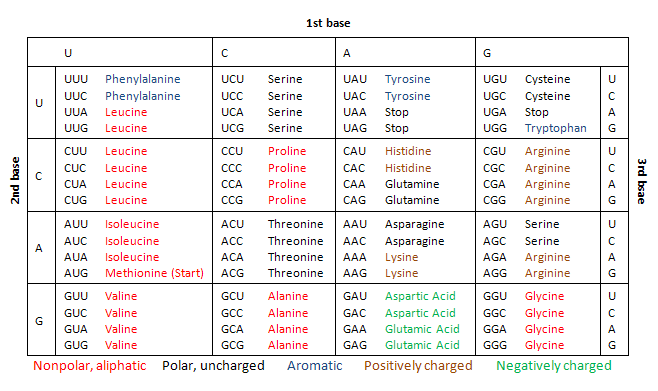
mRNA exits the nucleus of a eukaryotic cell via nuclear pores, it then comes into contact with a special protein called a ribosome. Ribosomes work together with strands of RNA called tRNA, which have 3 bases (a anti-codon) which are complementary to the codons present in mRNA. tRNAs basically are your cell's code-cracking sheets, as they are attached to the amino acid which correspond to the mRNA codon. The ribosome is effectively the machinery that sticks together the amino acids on the tRNA, eventually creating a protein. Proteins aren't usually folded by themselves, and often require assistance via a molecular "chaperone," a family of proteins called chaperonins. There are 64 combinations of codons, all of which correspond to an amino acid, found on tRNA. Here is a table:
Nucleic Acid Denaturation
As mentioned previously, DNA and RNA is incredibly stable - however, because of the need to replicate DNA for meiosis and mitotic cell division, the secondary structure must not be too stable. If DNA and RNA where to be too stable, replication and gene expression rely on the uncoiling, and recoiling of double-stranded nucleic acids. Physiological conditions (~pH = 7, 298.15 K (25 ℃), 1 atm) allow cells to be opened up by the required enzymes in vivo.
But what happens if a nucleic acid's secondary structure opens up too much? If the secondary structure is lost, it is called denaturation. Separating strands, like all things in chemistry, obey thermodynamic laws, in this case the free energy change:
ΔG = ΔH - TΔS (helix ⮂ random coil)
The secondary structure is stabilised by phosphodiester bonds, hydrogen bonds and base stacking, as mentioned in the previous sections. These interactions contribute to the heat of a nucleic acid system, i.e. they are enthalpic, so ΔH in the equation above will be positive. And since helices are very ordered, the entropy change, once denatured, will result in a positive ΔS.
Low temperatures result in a lower ΔG, because the - TΔS portion of the equation is positive, due to a reduction in randomness because of a lower temperature. This results in a ΔG > 0, meaning the helix is relatively more stable than at higher temperature. As such, when the temperature increases, - TΔS becomes greater than the ΔH value, resulting in ΔG < 0, which decreases the stability of the helix, eventually the double helix falls apart. It is possible that slowly cooling can reverse this process.
Denaturation of nucleic acids can actually be observed through a spectrometer set at the ultra-violet range (260 nm) when slowly heating a solution of DNA. When doing this, you would notice that the absorbance of the solution increases over time as the purine and pyrimidine structures become more "free." This happens because the structure of DNA, where nucleotides are packed in tightly in a double helix results in a decrease in light absorption, a process called hypochromism.
Futher reading on 'Junk-DNA' :
- https://www.abebooks.com/9780231170840/Junk-DNA-Journey-Dark-Matter-023117084X/plp
- http://www.pnas.org/content/111/17/6131
- https://books.google.co.nz/books/about/Non_coding_RNAs_and_Epigenetic_Regulatio.html
As always, thanks for reading!
Links provided bring you to some of the info I used, the first year university textbook, "Biochemistry: Concepts and Connections," 1ED, by D.R. Appling, Pearson Ed. LTD. Chapter 4: Nucleic Acids, pgs 126-129, was used as a guide to write this post. You can buy it here.
I also used the textbook, "Molecular Biology," 5ED, by Weaver, Robert F., McGraw HIll Publishing; which if you're interested (and have the money to spare). Chapter 3: An Introduction to Gene Function, pgs 31-45, was used as a guide to write this post. You can buy it here.
No comments:
Post a Comment